
How to Employ Programmatic Solutions to Conquer Disk Failures: A Guide to Optimizing Data Throughput and Reliability in Kafka using ZFS
By: Kumar Ravi Shankar
Kafka is a popular distributed streaming platform renowned for its ability to manage and optimize substantial data streams. However, with its widespread adoption comes insights into the vulnerabilities inherent in its distributed architecture and the demanding throughput requirements it necessitates. These vulnerabilities include the potential for disk failures and a range of other issues, such as network outages, hardware failures, software bugs, configuration errors, overload conditions, and security breaches. The existence of these risks poses a significant threat to the performance, availability, and data integrity of the Kafka streaming platform.
This article presents a systematic approach to mitigate the risks associated with disk failures in Kafka by leveraging ZFS (Zettabyte File System). Initially, we investigate the five key advantages of integrating ZFS to address disk failure challenges within Kafka. Then, we provide a comprehensive 11-step guide to implementing ZFS as the designated file system and logical volume manager for Kafka. This implementation is designed to fortify data reliability by effectively shielding against potential disk failures.
Comparing Kafka’s Fire-and-Forget Model With its Three Acknowledgement Models
In the Fire-and-Forget model within Kafka, producers send messages to a Kafka topic without pausing for acknowledgment or confirmation from the broker or consumers. Once the message is dispatched, the producer proceeds without blocking or waiting for a response, enabling swift processing. This model prioritizes high throughput and non-blocking communication, albeit at the cost of potential data loss if messages aren’t processed successfully.
Kafka offers distinct acknowledgment modes that producers can tailor to their preference, striking a balance between data reliability and system performance. These acknowledgment modes are determined by the “acks” configuration parameter. Here are the three prevalent acknowledgment modes:
1. Acknowledgment All (acks = all)
In the “acknowledgment all” mode, producers necessitate acknowledgments from all in-sync replicas (ISRs) associated with the topic partition once a message is published. The producer waits until acknowledgments are received from all replicas before deeming the message as successfully published. This mode ensures the most robust data reliability guarantee by confirming that all replicas have indeed received and acknowledged the message. While offering superior durability, it may potentially affect throughput and latency due to the increased synchronization demands.
2. Acknowledgment One (acks = 1)
In the “acknowledgment one” mode, producers seek acknowledgment from the leader replica of the topic partition upon message publication. Upon successful reception of the message by the leader replica, the producer deems it as successfully published. This mode strikes a balance between data reliability and performance, ensuring that at least one replica has acknowledged receipt of the message. This approach offers a moderate level of reliability while sustaining a reasonable throughput.
3. Acknowledgment Minus One (acks = -1 or acks = all / -1)
The “acknowledgment minus one” mode amalgamates elements from both “acknowledgment all” and “acknowledgment one.” In this mode, the producer doesn’t mandate acknowledgments before marking the message as successfully published. It promptly proceeds with processing, devoid of acknowledgment delays. However, it still awaits confirmation of the message being written to the leader replica to ensure durability. This mode optimizes for the highest throughput while offering the least data reliability guarantee, as acknowledgments are not a requirement.
To summarize:
If acks=0 -> Just fire and forget. Producer won’t wait for an acknowledgement.
If acks=1-> Acknowledgement is sent by the broker when message is successfully written on the leader.
If acks=all -> Acknowledgement is sent by the broker when message is successfully written on all replicas.
The selection of acknowledgment mode hinges on the intended trade-off between data reliability and system performance. “Acknowledgment all” ensures the highest durability but might affect latency and throughput. On the other hand, “acknowledgment one” strikes a balance between reliability and performance. Meanwhile, “acknowledgment minus one” prioritizes maximum throughput but may involve certain compromises in data reliability.
Data Throughput and Data Reliability Tradeoffs
As depicted earlier, the Fire-and-Forget model emphasizes speed, bypassing acknowledgments to boost throughput but at the expense of a higher risk of data loss. Conversely, acknowledgment modes introduce acknowledgment processes to enhance reliability, albeit potentially impacting latency and reducing throughput to varying degrees.
Ultimately, the selection between the Fire-and-Forget model and acknowledgment modes hinges on specific application requirements. When data loss is intolerable and higher reliability is paramount, acknowledgment modes like “acknowledgment all” or “acknowledgment one” are typically adopted. However, if maximizing throughput and minimizing latency are the primary objectives, the Fire-and-Forget model is preferred, acknowledging the associated tradeoff in data reliability.
The tradeoff manifests in the trade of higher data reliability against reduced data throughput. Mechanisms such as replication, acknowledgment modes, and synchronization among replicas introduce added overhead and latency, potentially impacting the overall system throughput. Conversely, prioritizing higher data throughput may entail compromising some reliability, as swift processing may leave limited time for replication or acknowledgment.
Determining the optimal balance rests on the specific demands of the use case. Certain applications may prioritize peak throughput, accepting an elevated risk of potential data loss or short-term inconsistencies. Conversely, other use cases like financial systems or critical data pipelines may prioritize data reliability and durability, even if it entails a slightly lower throughput. Kafka provides configurable parameters like acknowledgment modes, replication factors, and durability settings to strike the desired equilibrium between data throughput and reliability, aligning with the application’s prerequisites.
Problems That Result From Disk Failures in Kafka
Apache Kafka stands as one of the leading open-source distributed streaming platforms today, lauded for its outstanding capacity to handle extensive data streams. Embraced by over 80% of the Fortune 100, it presents a multitude of advantages for organizations seeking real-time data, stream processing, integration, or analytics.
However, given its fundamental design as a distributed streaming platform, Kafka operates across diverse nodes and brokers, rendering it susceptible to various failure types, notably disk failures. Within Kafka, disk failures can result in detrimental outcomes such as data loss, corruption, and cluster outages, incurring significant costs for organizations.
Unforeseeable disk crashes within brokers can trigger downtime across the entire cluster, disrupting partition availability. Restoring a Kafka cluster following a disk failure may unfortunately lead to some data loss. In the absence of robust mechanisms, there exists no inherent parity solution to recover corrupted data blocks. Addressing disk failures might necessitate restarting multiple services at the cluster level. Consequently, safeguarding against disk failures stands as a pivotal consideration when deploying Kafka in production environments, paramount for ensuring the reliability of data.
What is ZFS?
ZFS, or Zettabyte File System, represents a unified file system and logical volume manager originally conceived by Sun Microsystems (now under Oracle Corporation). This sophisticated and scalable file system was engineered to overcome the limitations and hurdles posed by traditional file systems.
Renowned for its versatility, ZFS offers an extensive array of features and functionalities, making it highly favored in diverse settings such as enterprise storage systems, data centers, and high-performance computing. The advantages of employing ZFS as a file system and logical volume manager encompass its scalability, robust safeguards against data corruption, compatibility with substantial storage capacities, efficient data compression, seamless integration of filesystem and volume management functionalities, capabilities for snapshots and copy-on-write clones, continuous integrity checks, and automated repairs. Additionally, ZFS offers software-defined RAID pools to ensure disk redundancy, enhancing data reliability.
In essence, ZFS furnishes a formidable and scalable file system solution enriched with features that bolster data integrity, reliability, and storage management. Its advanced capabilities render it well-suited for a wide spectrum of applications and storage environments.
ZFS as a Programmatic Solution to Disk Failures in Kafka
The primary objective of this whitepaper is to delve into the utilization of ZFS as a programmatic remedy for mitigating disk failures in Kafka. Given ZFS’s manifold advantages, encompassing efficient I/O utilization, automatic checksumming, and pooled storage, it stands as an optimal choice to uphold data integrity and availability within Kafka setups.
The integration of ZFS as both the file system and logical volume manager for Kafka holds the potential to significantly elevate data reliability and fortify defenses against disk failures. Within this framework, Kafka reaps the benefits of optimized I/O utilization, automatic checksumming, and the advantages of pooled storage. By establishing software-defined RAID pools, ZFS ensures data redundancy and sustained availability, even when confronted with disk failures. Additionally, the adaptable nature of incorporating or removing buffer disks facilitates dynamic adjustments to evolving storage needs.
Let’s thoroughly investigate these advantages of utilizing Kafka on ZFS initially, followed by a comprehensive walkthrough of the 11 essential steps. These steps will empower you to confidently configure ZFS for Kafka, leveraging its resilient features to construct a steadfast and robust streaming platform.
Note: The implementation steps outlined in this whitepaper are a condensed guide and should be tailored to align with specific system configurations.
Functionality Improvements From Using ZFS With Kafka
Leveraging ZFS alongside Kafka yields notable functional enhancements:
Improved Broker Read Performance
ZFS features a file system cache, significantly enhancing broker read performance in Kafka. This cache effectively stores frequently accessed data in memory, reducing the need for repetitive disk fetching. This translates to reduced latency and accelerated data retrieval, ultimately enhancing the overall performance and efficiency of the distributed streaming platform.
Efficient I/O Utilization
The design of ZFS enables it to maximize I/O operations through adaptive read and write algorithms, intelligent caching mechanisms, and parallelized I/O across multiple disks. This efficiency minimizes latency, improves throughput, and allows Kafka to handle large-scale data streams more effectively, enhancing data processing and system performance.
Pooled Storage
Users of ZFS can take advantage of pooled storage, enhancing data availability and resilience. In this architecture, disk failures within the pool don’t significantly impact the overall storage system, as data is distributed across multiple disks, ensuring redundancy and fault tolerance. In case of a disk failure, ZFS reconstructs data from remaining disks, preserving data availability and minimizing the risk of data loss, making it ideal for critical data streaming applications like Kafka.
Automatic Checksumming
ZFS within Kafka provides automatic checksumming, enhancing data integrity by performing checksum calculations on stored data. This process detects and handles corrupted data blocks, utilizing parity information to rebuild and restore the block without requiring system downtime. Automatic checksumming effectively maintains data integrity and minimizes the risk of data loss or inconsistencies.
Virtual Volumes
ZFS supports dynamic volume management through virtual volumes. This feature allows Kafka users to easily add or remove buffer disks, adapting storage infrastructure to changing data demands, optimizing resource usage, and reducing costs. Seamless volume allocation and deallocation simplify volume management, enabling efficient scaling of data processing capabilities in Kafka environments.
Snapshots and Clones
The snapshot and copy-on-write clone capabilities facilitate efficient point-in-time copies of Kafka data. Snapshots enable capturing data states without duplicating the entire dataset, aiding in data backups, testing, and versioning. Clones offer writable snapshots, providing independent copies of a dataset, beneficial for creating various Kafka cluster instances for different purposes. ZFS enhances data management flexibility and versatility within Kafka deployments through these capabilities.
Advantages of Integrating ZFS with Kafka
The enhancements listed above provide a host of advantages, including:
Robust Data Integrity
ZFS ensures comprehensive defense against data corruption through its integrated checksumming mechanism. This feature guarantees the preservation of data integrity within Kafka by verifying each data block written to Kafka topics. By automatically detecting and mitigating potential corruption issues, ZFS assures users that their Kafka data remains secure and unaltered, reinforcing the overall reliability and trustworthiness of Kafka deployments.
Ample Storage Capacities
There is substantial storage capacity within ZFS, which is particularly beneficial for Kafka deployments managing extensive data volumes. This support allows organizations to effortlessly scale their storage infrastructure to meet the escalating demands of high-throughput Kafka systems. By leveraging ZFS’s capability to handle large storage capacities, Kafka deployments can effectively manage and process large-scale data streams without being restricted by storage limitations, ensuring uninterrupted data processing even in demanding environments.
Efficient Data Compression
ZFS offers efficient data compression algorithms, leading to noteworthy reductions in storage space requirements for Kafka topics. This capability optimizes storage utilization, potentially reducing associated storage costs, and enhancing system performance by minimizing the amount of data read from or written to disk. By efficiently compressing data while maintaining its integrity, ZFS empowers Kafka deployments to scale effectively and accommodate larger data volumes.
Enhanced Data Consistency and Reduced Corruption Risk
Integrity checks are conducted continuously on stored data, using checksums to verify block integrity. In the event of errors, ZFS automatically repairs corrupted blocks using redundant copies or parity information. This proactive approach to data integrity ensures data consistency and reliability, significantly reducing the risk of data corruption. By bolstering data reliability and durability, ZFS becomes invaluable for mission-critical applications where data integrity is paramount.
Assured Data Availability and Durability
ZFS provides data availability and durability through software-defined RAID pools, allowing administrators to configure disk redundancy effectively. By distributing data across multiple disks with redundancy, ZFS guarantees data accessibility and integrity, even in the face of disk failures. This high availability and durability are crucial for Kafka deployments, ensuring uninterrupted data processing and minimizing the impact of hardware failures.
Integrating ZFS with Kafka offers a wealth of advantages, including heightened data integrity, scalability, storage efficiency, and robust data protection. These advantages collectively solidify ZFS as a valuable choice for creating reliable and resilient Kafka deployments.
Implementing Kafka on ZFS: An 11-Step Process
Below are the detailed steps to seamlessly integrate Kafka with ZFS:
Step 1: Check the Current CentOS Version
To ascertain the CentOS version on your server, run the command “cat /etc/redhat-release” in the terminal. This command will present crucial CentOS Linux release information, aiding in system compatibility checks and troubleshooting.
Step 2: Add the ZFSOnLinux Repository
Incorporate the ZFSOnLinux repository using the provided command, ensuring access to essential ZFS components and updates.
Step 3: Update ZFS Repository with kABI
Update the ZFS repository to utilize kABI as the module loader, a pivotal step for ensuring ZFS compatibility and functionality.
Step 4: Install ZFS File System
Execute the specified command to install the ZFS file system on CentOS 7, enabling utilization of ZFS functionalities.
Step 5: Load ZFS Kernel Module
Load the ZFS kernel module and confirm its status, ensuring that ZFS is properly integrated and operational.
Step 6: Create ZFS Pools (data1 and data2)
Establish two ZFS pools, data1 and data2, based on the server’s disk configuration, an essential foundation for ZFS storage management.
Step 7: Fine-Tune ZFS Configurations
Optimize ZFS configurations to enhance system performance and reliability, tailoring settings to suit specific requirements.
Step 8: Set L2ARC Configurations
Configure L2ARC (Level 2 Adaptive Replacement Cache) settings to optimize caching, enhancing performance and data access speed.
Step 9: Enable Auto-Import on Reboot
Ensure ZFS pools are automatically imported upon server reboot, maintaining data availability and system efficiency.
Step 10: Reboot the Server
Initiate a server reboot to complete the ZFS setup, ensuring all configurations take effect seamlessly.
Step 11: Set Up Pulse Alerts for Monitoring
Establish alerts using Pulse to monitor and receive notifications for kernel-level errors and disk issues, enabling prompt detection and resolution of potential concerns.
Let’s look at these comprehensive steps in more detail, below.
A Detailed Guide for Implementing Kafka on ZFS
This guide will walk you through the 11 essential steps, accompanied by screenshots, to set up Kafka on ZFS:
STEP 1: Verify the Current CentOS Version
To confirm the current CentOS version on your server, execute the command “cat /etc/redhat-release” in the terminal. This command reveals vital CentOS Linux release details, aiding in system troubleshooting and ensuring compatibility with software and updates.

STEP 2: Incorporate the ZFSOnLinux Repository
To seamlessly add the ZFSOnLinux repository, execute the following provided command: “yum install http://download.zfsonlinux.org/epel/zfs-release.el7_9.noarch.rpm". This command efficiently downloads and installs the necessary repository package, granting you access to install the ZFS file system on your CentOS 7 server.
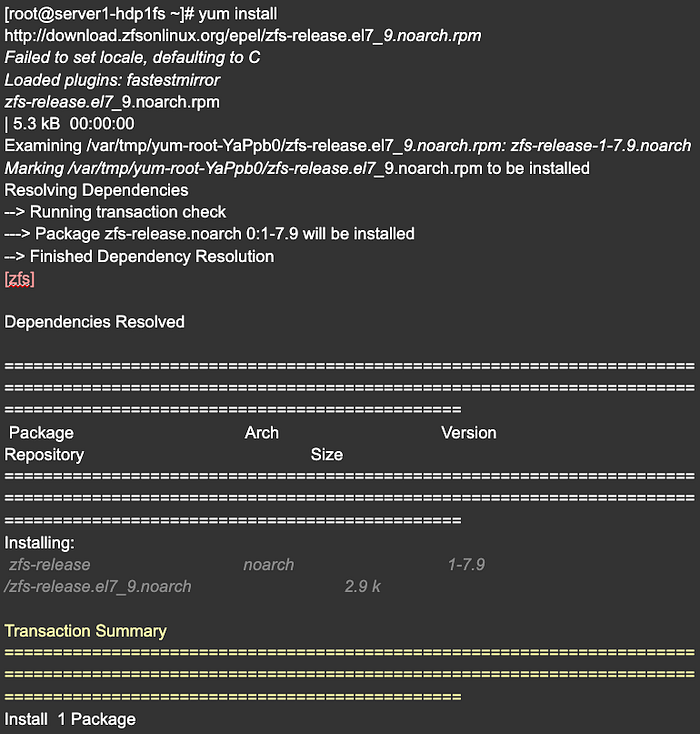
STEP 3: Optimize ZFS Repository with kABI for Module Loading
Enhancing the ZFS repository to utilize kABI as the module loader entails deactivating the DKMS (Dynamic Kernel Module System) repository while enabling the kABI (Kernel Application Binary Interface) repository. This step holds significant importance as it streamlines the module loading process without necessitating recurrent recompilations, contrasting with the DKMS approach that mandates recompilation each time the CentOS kernel is updated.
By transitioning to kABI, the ZFS module can be effortlessly integrated into the kernel without the burden of frequent recompilation, ensuring a more efficient and convenient solution for seamless operation. Upon installing the ZFS repository on CentOS 7, the DKMS-based repository is typically enabled by default. Therefore, disabling DKMS and enabling the kABI-based repository optimizes the module loading mechanism, improving system efficiency and stability.
This is the final configuration:
- In zfs section set, enabled=0
- In zfs-kmod section set, enabled=1
STEP 4: Install the ZFS file system on CentOS 7 using the given command
To install the ZFS file system on CentOS 7, you can use the command “yum install zfs”. This command will download and install the necessary packages and dependencies for ZFS. Once the installation is complete, you can verify the installation by checking the ZFS kernel module using the “lsmod | grep zfs” command.

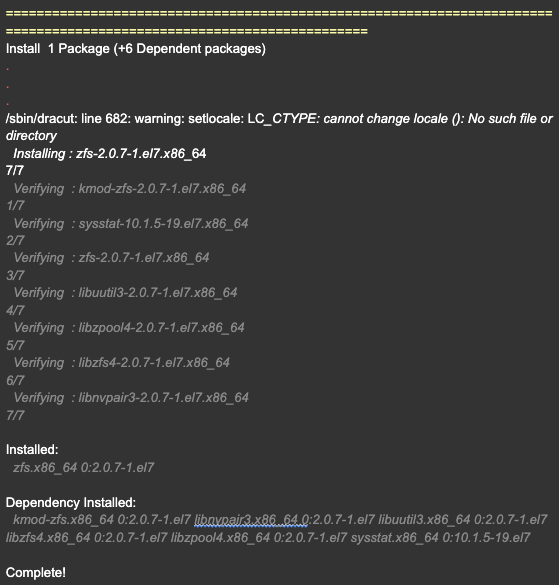
STEP 5: Load the ZFS kernel module and verify its status
To load the ZFS kernel module, run the command “modprobe zfs” in the terminal. After loading the module, you can verify its status by running “lsmod | grep zfs” to check if it appears in the list of loaded modules. The output should display information about the ZFS module, confirming that it has been successfully loaded.

There are three types of pools that can be created in ZFS:
- Stripped Pool
- Mirrored Pool
- Raid Pool
Reference Link for more information related to types of zfs pool as per the required use case : https://www.thegeekdiary.com/zfs-tutorials-creating-zfs-pools-and-file-systems/
We will opt for a RAID pool, and in ZFS, all RAID-ZX configurations operate similarly, differing mainly in disk tolerance. RAID-Z1, RAID-Z2, and RAID-Z3 can tolerate a maximum of 1, 2, and 3 disk failures, respectively, without experiencing any data loss.
Regarding the “ashift” property in ZFS, it allows manual configuration of the sector size on SSDs. For example, setting “ashift=12” implies a sector size of 2¹², or 4096 bytes. There’s no penalty for setting “ashift” too high. However, if it’s set too low, a substantial read/write amplification penalty is incurred. Writing a 512-byte “sector” to a 4KiB real sector necessitates writing the initial “sector,” reading the 4KiB sector, modifying it with the second 512-byte “sector,” and writing it back out to a new 4KiB sector. This process is repeated for every single write, leading to significant amplification in read and write operations.
STEP 6: Create two ZFS pools (data1 and data2) based on the server’s disk setup
Create 2 zpools (data1 and data2) based on the disk OS is setup:
- sudo zpool create -o ashift=12 -f data1 raidz1 sda sdb sdc sdd
- sudo zpool create -o ashift=12 -f data2 raidz1 sdf sdg sdh sdi
– OR –
- sudo zpool create -o ashift=12 -f data1 raidz1 sdb sdc sdd sde
- sudo zpool create -o ashift=12 -f data2 raidz1 sdg sdh sdi sdj
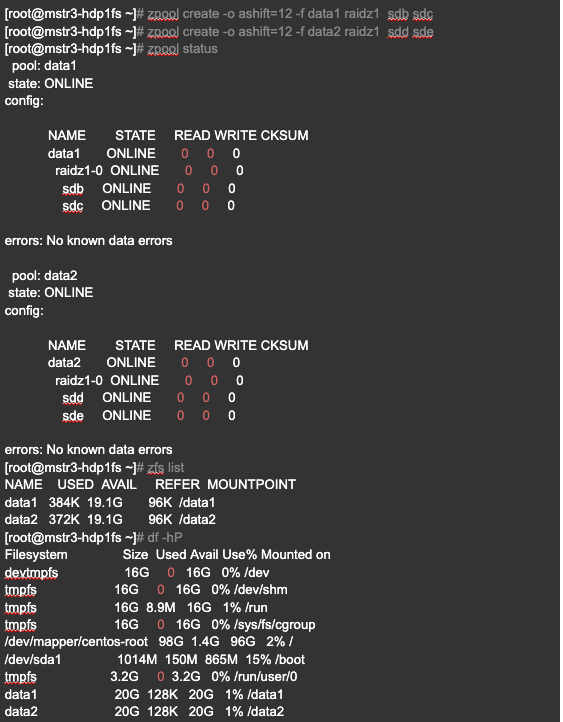
In this step, several ZFS configurations are adjusted to enhance performance and reliability. First, the “atime” property is disabled to improve I/O performance for frequently accessed small files. Second, the “redundant_metadata” property, which stores an additional copy of most block metadata, is set to “most” to enhance random write performance. Third, the extended attributes and process execution within the “data1” file system are controlled by disabling “xattr” and “exec” respectively. Lastly, the “overlay” property is set to “off” on every pool to expedite mount failure recovery. These fine-tuning measures aim to achieve better overall performance and reliability in the ZFS file system.
sudo zfs set atime=off data1
Disabling atime is a great way to improve I/O performance on filesystems with lots of small files that are accessed frequently.
sudo zfs set redundant_metadata=most data1
When set to most, ZFS stores an extra copy of most types of block metadata. This can improve performance of random writes, because less metadata must be written.
sudo zfs set xattr=off data1
Controls whether extended attributes are enabled for the ZFS file system.
sudo zfs set exec=off data1
Controls whether processes can be executed from within this file system.
sudo zfs set overlay=off data1
Set overlay=off on every single pool, for a faster mount failure recovery.
- sudo zfs set atime=off data2
- sudo zfs set redundant_metadata=most data2
- sudo zfs set xattr=off data2
- sudo zfs set exec=off data2
- sudo zfs set overlay=off data2
STEP 8: Set L2ARC (Level 2 Adaptive Replacement Cache) configurations for improved caching
The L2ARC is the 2nd Level Adaptive Replacement Cache, and is an SSD based cache that is accessed before reading from the much slower pool disks. The L2ARC is currently intended for random read workloads.
sudo vi /etc/modprobe.d/zfs.conf
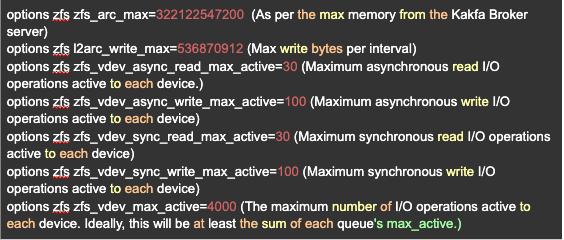
STEP 9: Enable the auto import on reboot
systemctl enable zfs-import-cache -l
systemctl start zfs-import-cache -l
STEP 10: Alert Setup from Pulse
ZFS setup for Kafka broker is completed now and it can be used for log.dir /data1 and /data2 with raidz1 to sustain 1 disk failure.
Important note: Please keep 2 disks in the buffer for the hot swapping with the bad disk in the zpool.
STEP 11: Setup Alert for any Kernel Level Error which includes exceptions for bad sector within the disk before crashing.
Achieving Balance In Kafka Environments
This article went quite deeply into the intricate challenges faced by standard file systems like XFS and ext4 when integrated into a Kafka cluster, especially in scenarios where the “acks=0” (Acknowledgment One) configuration is applied at the cluster level. A disk crash on a broker can trigger a cluster outage, leading to a -1 leader status for affected partitions. Restoring the cluster in such circumstances often results in data loss, especially when “unclean.leader.election.enable=true” is configured, and there’s a notable absence of a built-in parity mechanism to recover corrupted data blocks. The recovery process necessitates multiple restarts at the cluster level.
The proposed resolution advocates for a fundamental architectural shift from conventional XFS and ext4 file systems to the more robust ZFS. This transition significantly improves the cluster’s resilience to disk failures and unpredictable outages. The incorporation of parity checksums helps in the recovery or reconstruction of corrupted data blocks, effectively mitigating data loss. Additionally, this proposed solution eliminates the need for repetitive cluster-level service restarts, streamlining the recovery process.
However, it’s essential to acknowledge that implementing ZFS systems does come with a drawback — an increased storage requirement on each node. This encompasses the need to allocate space for spare disks and parity, impacting the overall storage capacity of the system.
Photo by Jakob Søby on Unsplash
